In: Peter Handler (Hrsg.) (2001): E-Text: Strategien und Kompetenzen. Elektronische Kommunikation in Wissenschaft, Bildung und Beruf. Frankfurt am Main u.a.: Peter Lang. S.81-93
Ich stelle MailTack, ein spezifisches e-Mail-Verwaltungsprogramm vor, das wir als Tool zum Indiviuellen Wissensmanagement entwickeln. Das Programm erlaubt die mehrfache Kategorisierung und Verknüpfung von e-mail-Segmenten. Ich diskutiere dabei das von uns verwendete Wissenskonzept, das auf unserer Interpretation des Radikalen Konstruktivismus beruht. Anstelle einer kollektiven Ontologie verwenden wir im Programm eine persönliche Konstellation von Kategorien, die wir als Wissensportfolio betrachten. Die kognitiven Anforderungen, die die Benutzung unseres Tool stellt, diskutiere ich anhand der Unterscheidung zwischen Metatext und Link, die Vannevar Bush in seinem Aufsatz "as we may think" implizierte.
I present MailTack, an e-mail-tool, wich we are still developing in the frame of individual knowledge management. The software tool supports the multiple categorisation and linking of e-mail-segments. Within the presentation I discuss our concept of knowledge, wich is based on our interpretation of radical constructivims. Instead of a collective ontology we use a personal constellation of categories to characterise the mails segments, wich we take as a knowledge portfolio. The kognitiv performance demanded by the use of our tool, i will discuss in relation to the distinction between Metatext and Link, wich was implied by Vannevar Bush, when he worte "as we may think".
Wissensmanagement ist zum Schlagwort geworden. Die meisten Applikationen, die unter diesem Label auftreten, lassen sich aber problemlos als Dokument- oder Datenmanagement begreifen. Wissensspezifische Aspekte werden kaum diskutiert - oder es wird kaum diskutiert, was Wissen in diesem Zusammenhang bedeuten soll. In unserem Verständnis muss das Wissensmanagement auf den Wunsch If I only knew what I know reagieren. Es geht uns also explizit nicht darum, neues Wissen zu schaffen oder vorhandene Wissensbestände zu verwalten, sondern darum, sich in Form eines Knowlegde Portfolios bewusst zu machen, was an Wissen wie vorhanden ist - was natürlich das retrieval von Dokumenten, das das mainstream knowledge management beschäftigt, mit einschliesst. Auch im kruden Wissensmanagement wird zwar von tacit knowledge gesprochen (Nonaka und Takeuchi 1995), damit ist aber meistens nicht das eigene sich seines Wissens nicht bewusstsein gemeint, sondern die Geheimnisse, die die andern "Mitarbeiter" zum Schaden der Firma nicht explizit machen, um ihren Marktwert zu erhalten.
Es gibt eine Art common sense darüber, dass Wissen im Unterschied zu Daten an Individuen gebunden ist. Unser individuelles Wissensmanagement focusiert aber nicht das individuelle Wissen, sondern individuelle Handlungen im Rahmen des Wissensmanagement.
Im konventionellen Wissensmanagement geht es darum, eine Daten-Ordnung zu (er)finden, die vordergründig für alle Beteiligten möglichst gut nachvollziehbar ist, so dass alle ihr Wissen in Form von Daten so charakterisieren und ablegen, dass es von allen andern "Mitarbeitern", die der Firma Gutes wollen, gefunden werden kann. Das etwas durchsichtige Konzept dazu heisst Ontologie (Seinslehre) und suggeriert, dass die Daten eine Wirklichkeit widerspiegeln und dass es - in Näherung zu diesem wirklichen Sein - eine wahre Datenordnung gibt, auf die man sich wenigstens intersubjektiv einigen kann und sollte. Dieses datenorientierte Wissensmanagement ist von zwei Seiten angefochten: von logischen Eichhörnchen und von unlogischen Robotern. Von den Eichhörnchen lernen wir, dass wir uns nicht merken müssen, wo wir Daten ablegen. Die Eichhörnchen merken sich nämlich auch nicht, wo sie ihre Eicheln vergraben. Wenn sie im Winter Eicheln suchen, schauen sie einfach dort, wo sie die Eicheln vergraben würden, und dort finden sie dann "logischerweise" Eicheln. Die Roboter merken sich auch nicht, wo sie die Daten ablegen. Sie schauen im Bedarfsfall einfach "schnell" alle Daten durch, und finden dann die gesuchten Daten natürlich auch. Die ausgedacht richtig klugen Roboter machen während des sogenannten data minings gleich noch semantische Ueberlegungen, so dass sie auch im gröbsten Chaos nur die wirklich relevanten Daten finden.
Wir sind weder Eichhörnchen noch Roboter. Wir haben andere Gründe anzunehmen, dass sich unser Wissen nicht in kollektiven Begriffs-Ontologien repräsentieren lässt. Ich will unseren individuellen Ansatz im Wissensmanagement anhand einer Software vorstellen, die wir im Rahmen eines europäischen Forschungsprojekts entwickeln. Es handelt sich um ein Tool, das seinen Benutzer bei seiner e-mail-Kommunikation unterstützt. Dabei erläutere ich auch die theoretischen Hintergründe unserer Wissensauffassung. Schliesslich will ich unsere Arbeit am Begriffspaar Metatext versus Links in einem grösseren Rahmen problematisieren.
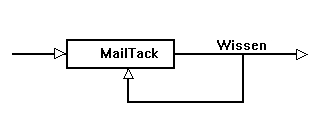
MailTack ist ein Softwaretool, mit welchem Teile von verschiedenen e-Mails kategorisiert und zu Argumentationsketten verbunden werden können; jede Kette kann entweder als zusammenhängender Text oder als Graph von verknüpften Knoten im globalen Graph der gesamten Diskussion angeschaut werden. MailTack ermöglicht es also, aus einer Vielzahl von Mails mit verschiedenen Partnern jene Teile zu selektionieren und zusammenzufügen, die ein Thema betreffen. Viele Mails enthalten Beiträge zu verschiedenen Themen und viele Mails enthalten Beiträge wie Terminabsprachen, die nur im aktuellen Moment interessieren. Mit MailTack filtert man die wichtigen Teile zu einem Thema zusammen.
MailTack wird - wie etwa Outlook, zu welchem es eine Datenschnittstelle hat - nicht auf dem Server, sondern auf dem eigenen, lokalen PC installiert. Es ist also ein individuell benutztes Programm, mit welchen jeder Benutzer seine eigene Sicht auf die Gruppenprozesse modelliert. Für verschiedenen Teilnehmer eines Kommunikationsprozesses sind normalerweise nicht alle Teile von gleicher Relevanz. Ausserdem sind die verschiedenen Teilnehmer eines Projektes normalerweise in verschiedene andere Projekte involviert, so dass sie verschiedene Querbezüge machen und die e-Mails auch deshalb verschieden gewichten und sortieren.
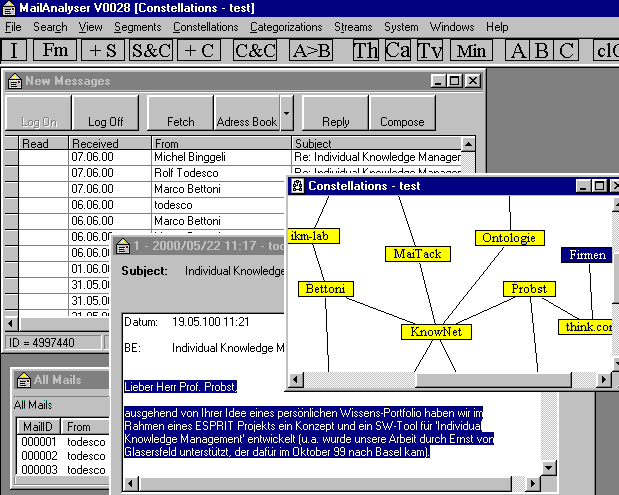
MailTack ist Teil von zwei verschiedenen Projekten. Konzeptionell ist MailTack Teil von KnowPort (www.ikm-lab.ch), und realisiert wurde MailTack als Teil des EU Esprit applied-research-Projektes (IT for Learning and Training in Industry) "KnowNet" (www.know-net.org). Im KnowPort-Projekt ist MailTack ein Spezialfall einer allgemeineren Strategie, die ich hier erläutern werde, im EU-Projekt KnowNet ist MailTack ein konkretes Tool im Rahmen einer umfassenden Wissens-Management-Applikation, die "Knowledger" heisst und auf Lotus Notes basiert.
Die Knowledger-Applikation wurde für das sogenannte corporate knowledge management entwickelt. Die Entwickler "Knowledgeassociates" wollten im Rahmen des KnowNet-Projektes das bestehende Tool weiterentwickeln. Ziele waren die Integration einer Ontologie für Wissensobjekte, die Einbindung von sogenannt intelligenten Agenten (robots) und nebenbei die Entkoppelung von Lotus Notes. Das KnowNet Tool ist eine Serverapplikation. Die Projektpartner haben dieses Tool während des Projektes als gemeinsame Wissens-Plattform benutzt.
Etwas skeptisch beurteilt war der Knowledger am Anfang des Projektes im wesentlichen eine heterogene Dokumentverwaltung, in welcher verschiedene Dokument-Typen spezifiziert werden können - und das ist er während des Projektes durch das Hinzufügen von weiteren Tools wie MailTack immer mehr geworden. Die Kernidee des Knowledegers besteht darin, Dokumente als "Wissensobjekte" zu deklarieren und über eine Ontologie zugänglich zu machen. Die Ontologie kann von einem "Wissensmanager" jederzeit verändert werden, wenn die Benutzer diesen Bedarf anmelden. Im Projekt ging es diesbezüglich darum, die Ontologie als Softwaretool mit graphischer Oberfläche und einem Editorprogramm verfügbar zu machen und einzubinden, und natürlich auch darum, eine Ontologie für den Projektzusammenhang aufzubauen.
Know(ledge) Port(folio), aus welchem das Konzept zu MailTack stammt, ist ein praktisches Projekt, in welchem wir die Theorie des Radikalen Konstruktivismus anwenden und auf den Begriff bringen wollen. Wir nehmen dabei den Ausdruck Konstruktivismus in einem spezifischen Sinn wörtlich: es geht uns um Konstruktionen. Wir erachten aber nicht "die" Wirklichkeit als konstruiert, sondern unsere Erklärungen. Als Erklärungen akzeptieren wir Beschreibungen von Mechanismen, mit welchen wir das zu erklärende Phänomen erzeugen können. Beschreibungen von Mechanismen betrachten wir dann als vollständig, wenn wir die Mechanismen auch wirklich herstellen können. In diesem Sinn ist unsere Forschung Engineering und unsere Mechanismen sind Softwaretools.
Wissen im Kontext des Wissensmanagemnt verstehen, bedeutet unter dieser Perspektive Werkzeuge konstruieren, die uns in unseren Wissensprozessen unterstützen. Als Wissensprozesse betrachten wir in diesem Zusammenhang - das zeigen uns eben unsere Werkzeuge - Prozesse, in welchen Texte (oder Symbole) eine Rolle spielen (können). Im KnowPort haben wir verschiedene Textcharakterisierungen als Ausgangspunkte für Untersuchungen gewählt. Unter dem Label MailTack befassen wir uns mit e-Mails.
E-mails gehören zweifellos zu den best gelesenen Texten. Sie sind meistens kurz, aktuell und erheischen Antwort. Sie behandeln oft mehrere Themen oder Projekte und betreffen oft mehrere Leute. Sie sind Ausdruck eines spezifischen Falls der Kommunikation: Die Partner kommunizieren zeit und ortsverschoben in schriftlicher Form. Durch die Eigenschaften des e-mail-Mediums, vor allem durch dessen Schnelligkeit gegenüber der mittlerweile snail-mail genannten Briefpost und der damit verbundenen Reaktionszeiten, sind mail-Texte oft wie Gesprächsbeiträge. Das heisst, es werden viele Aktualitäten ausgetauscht, e-Mails sind eher wie Zeitungen als wie Bücher. Es werden oft Sequenzen von Rede und Gegenrede ausgetauscht und es sind oft mehrere Kommunikationspartner involviert, was in Briefen selten der Fall ist. Die einzelnen Mails enthalten oft Abschnitte zu verschiedenen Gegenständen und Anlässen, was in Aufsätzen oder Essays gewünschterweise nicht der Fall ist. Es werden oft wichtige und unwichtige Dinge in derselben e-Mail mitgeteilt. e-Mail haben in vielen Hinsichten einen eigenständigen Charakter.
Das Wissen ist in den Mails auf komplizierte Art verteilt. Viele Mails lassen sich keinem halbwegs eindeutigen Begriff zuordnen. Die gebräuchliste Art, Mails zu verwalten, ist, sie in einer Datenbank mit Suchfunktionen wie Sender, Datum oder Betreff zu speichern. Damit lassen sich einzelne Mails meistens relativ gut finden, aber die Rekonstruktion einer Mail-Diskussion über verschiedene Mail mit verschiedenen Partnern ist so sehr schwierig und aufwendig. Noch schwieriger ist es, sich einen Ueberblick zu verschaffen, zu welchen Themen man mit welchen Menschen kommuniziert hat, um daraus abzuleiten, wo wer - und vor allem man selbst - welche Kompetenzen im Wissens-Portfolio hat.
Wir verfolgen mit MailTack einen aktionsorientierten Ansatz, welcher sich auf unser Trace-your-Tack-Prinzip stützt: Protokolliere (trace) Dein Wissen im Laufe der Fahrt (on tack), um im Wissens-Ozean auf dem richtigen Kurs zu segeln! Wir konzentrieren uns also - anders als Eichhörnchen und Roboter - auf die Input-Seite der Dokumentenverwaltung, so dass das Retrieval an Bedeutung verliert.
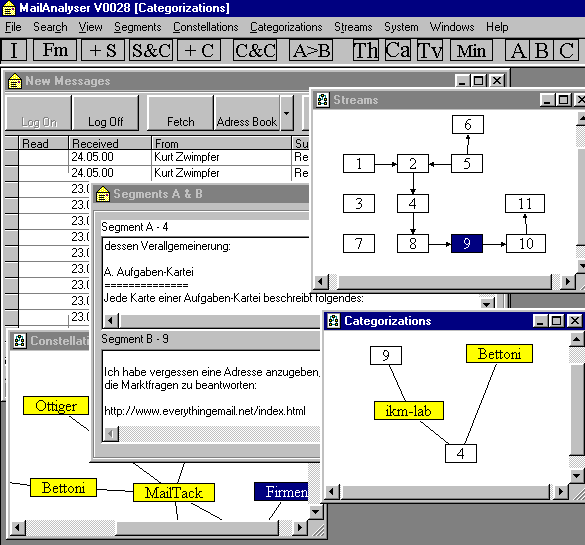
Während ich ein Mail lese, markiere ich mit dem Cursor das Textsegment, das mir in einem spezifischen Zusammenhang wichtig scheint. Bei vielen Mails markiere ich natürlich gar nichts. Dem markierten Textsegment kann ich eine oder mehrere Kategorien zuordnen, die ich in einem Fenster, in welchem meinen Kategorien und deren Verknüpfungen graphisch dargestellt sind, auswähle.
Die Segmente bleiben mit ihrem Herkunftsmail verknüpft, so dass ich den jeweiligen Kontext wiederfinden kann. Ausserdem kann ich die Segmente annotieren, und ich kann sie zu sogenannten Streams verknüpfen, so dass ich aus beliebigen Teilen aus verschiedenen Mails einen zusammenhängenden Text generieren kann. Die Streams lassen sich über die Kategorien der involvierten Segmenten aufgreifen. Und natürlich kann ich von jedem Segment sehen, wie ich es kategorisiert habe.
Wir nennen einen Datensatz, den wir mit MailTack erzeugen Wissensbasis. Damit die Ueberschaubarkeit erhalten bleibt, kann ich mit MailTack verschiedene, eigenständige Wissensbasen herstellen. Noch nicht programmiert, aber im Rahmen von KnowPort konzeptionell geleistet, ist die Möglichkeit nicht nur Mail-Segmente, sondern beliebige Dokumente in die Graphen einzubinden.
MailTack kann man ganz vordergründig auffassen. Dann dient MailTack als Werkzeug zum Verwalten von Mails, respektive von interessierenden Inhalten. Wir sehen den Nutzen eher auf einer weiteren Ebene: Mit der Anwendung von MailTack produziere ich eine persönliche Wissensbasis, in welcher ich mein Wissen fortlaufend widerspiegelt sehe. Die Portfolio-Idee hinter MailTack ist, dass sich in der Art, wie wir unsere Texte organisieren, ein wesentlicher Teil unseres Wissen zeigt. Die Analyse der Mails, die ich schreibe und erhalte, ergibt Auskunft darüber, womit ich mich beschäftige und mithin in welchen Gebieten ich Kompetenzen aufbaue. Und die Kategorien, unter welchen ich die Texte klassifiziere, zeigen mir, wie ich darüber denke. Mit MailTack generiere ich keine Ontologie darüber, wie die Welt wirklich ist, sondern eine Klassifikation, die wir Constellation nennen, die Ausdruck meiner Konstruktionen ist. In diesem Sinne macht die Verwendung von MailTack das eigene Wissen und das eigene Meta-Wissen darüber, wie man sein Wissen organisiert, bewusst.
Unser primäres Anliegen war nicht, ein Werkzeug zu schaffen, das man brauchen kann. Wir woll(t)en Forschen oder Wissen über Wissen schaffen. Forschen resultierte früher in Beschreibungen darüber, wie die Welt ist - also in eigentlichen Ontologien. Im Paradigma des Radikalen Konstruktivismus - wo es keine Wirklichkeit gibt, die man entdecken könnte -, ist Forschen logischerweise Konstruieren. Man muss die Wirklichkeit erfinden. Man kann in diesem Sinne operativ beschreiben, wie man Texte handhaben soll, oder konsequent weitergehend Werkzeuge herstellen, die bestimmte Handhabungen von Texten zulassen und unterstützen. MailTack ist eine Konstruktion.
Die Herstellung von MailTack, respektive das hergestellte Werkzeug macht explizit, wie wir uns diesen Bewusstwerdungsprozess vorstellen.
Wenn man ein Produkt herstellt, das man verkaufen will, kann man durch Umfragen erheben, was die Leute gerne hätten und was sie kaufen würden. In der Forschung scheint es mir ein ziemlich unsinniges Unterfangen, die Leute zu fragen, welche Forschungsresultate gefunden werden sollen. In unserem Projekt waren - nach einem gängigen Muster in der applied-Forschung - von Anfang an neben Entwicklern auch sogenannte User's, die ihre Anforderungen in den Entwicklungsprozess einbringen sollten. Wie aber sollten die Benutzer voraus wissen, was die Forschung zu tage bringt? Wir stellten uns auf den Standpunkt, dass wir selbst die Benutzer unseres Werkzeuges sind und so relativ unmittelbar Rückmeldung über die Funktionalität des Werkzeuges erhalten. Wenn das Werkzeug für uns brauchbar wird, dann können es vermutlich auch andere Menschen brauchen.
Vorderhand erscheint uns unser Werkzeug noch nicht praktisch, weil wir die Anforderungen, die MailTack im Gebrauch stellt, nur mit grossem intellektuellen und zeitlichen Aufwand erfüllen können. Das in der durch das Werkzeug vorgesehenen Art von Segmentieren und Klassifizieren von Texten erscheint uns nun als eine ungemein anspruchsvolle Aufgabe. Da wir selbst die Benutzer unseres Werkzeuges sind, können wir uns nicht, wie das in der Informatik verbreitet der Fall ist, damit trösten, dass das Werkzeug gut ist, aber die Benutzer nicht wissen, wie es zu verwenden ist - und noch weniger können wir irgendwelche Anforderungen von unbedarften Benutzern für das Werkzeug verantwortlich machen. In diesem Sinne erspart uns der Konstruktivismus eine aussichtslose Dialektik zwischen Entwicklern und Benutzern.
Durch unser Werkzeug gesehen verstehen wir Wissen als Handlungszusammenhang im Sinne eines funktionalen Systems. Wissen entsteht in diesem Sinne durch Tätigkeiten, die auf Wissen beruhen. MailTack verkörpert als Mechanismus Wissen, das zur Generierung von Wissen verwendet wird. Die Benutzung von MailTack setzt aber das Wissen, das mit MailTack entwickelt wird, in einem autopoietischen Sinne voraus. Dabei sind zwei Ebenen unterscheidbar. Zum einen das kategoriale Wissen, das in den verwalteten Texten und in deren Charakterisierungen repräsentiert ist, und zum andern das konstruktive Wissen, wie man den MailTack-Mechanismus weiterentwickeln muss. Als explizites Wissen erscheint nicht vor allem der Text, sondern der Mechanismus, mit welchem der Text organisiert wird. Natürlich ist auch dieser Mechanismus in Text darstellbar - und seine Weiterentwicklung geschieht sicher zunächst in Form von Beschreibungen neuer Spezifikationen, die ihrerseits Wissen verkörpern.
Die Schwierigkeiten, die sich aus den Benutzungsanforderungen von MailTack für uns ergeben, lassen uns MailTack und die darin verwendeten Konzepte neu sehen. Diese neue Sicht ist vorerst eine hypothetische Konstruktion auf der Ebene von Beschreibungen. Als Entwurf einer Weiterentwicklung ist sie eine Kritik im eigentlichen Sinne des Wortes, also eine Basis für einen Vergleich zwischen dem, was der Fall ist, und dem, wie wir uns die Sache vorstellen. Vor allem macht die Kritik die verwendeten Konzepte als solche bewusst, weil ihnen andere entgegengestellt werden. Von einer Entwicklung sprechen wir, wenn die neuen Konzepte die vorangegangenen nicht verwerfen, sondern als Spezialfall ausweisen, so wie die Relativitätstheorie die Mechanik als Spezialfall bestimmt, der bei relativ kleinen Geschwindigkeiten und relativ grossen Massen zutrifft.
Ontologien scheinen vorerst nicht daran zu scheitern, dass sie eine intersubjektiv wahrnehmbare Wirklichkeit voraussetzen, sondern daran, dass unsere Kapazität Ordner und Register nachzuführen sehr beschränkt ist - selbst dann, wenn wir sie wie die Constellation in MailTack ganz persönlich organisieren können. Die Ontologien im Wissensmanagement erscheinen uns nun als eine Gegenbewegung zu den Suchmaschinen bis hin zum sogenannten Datamining. Sie sind Ausdruck davon, dass man nicht nur finden muss, sondern auch eine kategoriale Ahnung davon haben sollte, was man finden will. Unser Trace-your-Tack-Prinzip ist in diesem Sinne ein Versuch, sich der eigenen Kategorien bewusst zu werden. Wenn die Textmenge, respektive die Inhalte eine gewisse kritische Grösse erreichen, ergeben sich aber Hyperphänomene - das Präfix "Hyper" steht für "über das Ziel hinaus schießen" - wie sie Vannevar Bush schon in den 40-er Jahren wahrgenommen hat: Entweder man verliert sich in der Menge der Kategorien, oder man macht die Kategorisierung so allgemein, dass sie nichts taugt.
Solange die Kategorisierung Dokumente aus Papier betrifft, ist quasi materiell gesichert, dass eine bestimmte Komplexität nicht überschritten wird. Die Grenzen der Verwaltbarkeit von Büchergestellen und beschrifteten Ordnern ist augenfällig. Auf der entwickelsten Produktivkraftstufe basiert die Organisation des expliziten Wissens aber in Computern, die Dokumente und die Zugriffszeiten werden verschwinden klein. Im Internet kann ich "Dokumente" beliebigen Textumfanges aus der ganzen Welt innerhalb von Sekunden auf meinen Computer holen. Gleichgültig was an Artefaktischem hinter den Datenverwaltungen in Computern steht, in allen widerspiegelt sich das Prinzip der Bibliotheken, in welchem die einzelnen Texte auf bezeichneten Plätzen abgelegt werden und in Registern aufgeschrieben wird, welcher Text wo zu finden ist - wenn ich Dokumente mit Kategorien charakterisiere. Dann befasst sich das Wissensmanagement weitgehend mit der Organisation der Register. Die globale Funktion der Register besteht darin, verschiedene Ordnungen über den Dokumenten darzustellen, dass diese unter verschiedenen Gesichtspunkten effizient und effektiv gefunden werden können.
Die einfachste Form des Registers ist eine implizite, nämlich die alphabetische Ablage der Dokumente. Dabei muss man bei gegebenem Alphabet - die Umlaute machen dieses Problem deutlich - nur festlegen, welches Wort des Dokumentes als Schlüsselwort für die Registrierung verwendet wird. Im Telefonbuch sucht man beispielsweise nach Angaben über einen Meier und findet diese Angaben unter dem Stichwort Meier, weil das Schlüsselwort ein Teil der Angaben ausmacht. Man kann diesen Fall als nichtausdifferenzierten Index verstehen. In einem solch impliziten Register kann man die Stellen, wo der alphabetisch nächste Wörterbereich beginnt, beispielsweise mit plastifizierten Zwischenbättern - die wir auch Register nennen - oder ähnlichem deutlich machen. Ein explizites Register ist eine gegenüber den eigentlichen Texten eigenständige Liste. Auf solchen Listen kann man beliebig viele Relationen definieren. In der Bibliothek verweist beispielsweise je ein Eintrag aus der Autorenkartei, aus der Buchtitelkartei und aus der Sachgebietkartei auf dasselbe Buch. Explizite Register verweisen auf ein Ur-Register, das den Ort der eigentliche Texte repräsentiert, quasi den Wohnort eines Buches im Gestell.
Die Art der Verweise auf dieses Ur-Register richtet sich nach dem Zweck oder der Funktion der Verweise. Ich unterscheide zwei grundsätzliche Fälle, die in Büchern mit Stichwortregister oder Inhaltsverzeichnisse und Literaturangaben oder Fussnoten beide realisiert sind. Stichwortregister und Inhaltsverzeichnisse sind aus dem Text ausgelagerte Verweise, die in den Text hinein zeigen, Literaturangaben und Fussnoten sind Verweise, die aus dem Text hinaus zeigen. Im ersten Fall sind die Verweise als Stichworte in einer Liste, die Verzeichnis oder Index heisst. Im zweiten Fall sind die Verweise über den Text verteilt, also kein eigenes Dokument. Seit der Verbreitung des Internets nennen wir solche Verweise häufig (Hyper-)Links. Indexe führen zu einer bestimmten Stelle im Text. Links öffnen den Text in einen umfassenderen Kon-Text.
Während Links Bestandteile des eigentlichen Textes sind, sind die Stichwörter in den Registern im einfachsten Fall dupliziert. Im Inhaltsverzeichnis eines Buches stehen normalerweise duplizierte Titel von Kapiteln und die Seitenzahl, wo dieser duplizierte Textteil nochmals zu finden ist. Im Namensregister am Ende eines Buches stehen etwa alle Seiten auf denen die Buchstabenkette Meier auch zu finden ist. Das eigentliche Register zeichnet sich dadurch aus, dass es nicht wie ein Inhaltsverzeichnis durch die Titel der Kapitel der Erzähllogik des Buches unterworfen ist. Die Schlüsselwörter in den Registern folgen Ordnungen, die vom Buch weitgehend unabhängig sind. Es handelt sich um Ordnungen, die quasi quer zur Ordnung des Buches stehen. Ich kann im Register ganz unabhängig vom Inhalt des Buches schauen, wie oft Marx zitiert wurde, oder wie oft von der Evolutionstheorie gesprochen wird. In diesem Sinne kriege ich durch die Register zusätzliche Sichtweisen auf ein Buch. Mittels Register kann ich über Stichworte Textstellen wiederfinden, die ich mit bestimmten Stichworten in Verbindung bringe. Wenn ich etwas über Darwin wissen will, dann kann ich unter Evolution schauen und umgekehrt. Und wenn ich mich erinnere, dass in einem bestimmten Buch im Zusammenhang mit der Evolution von Erdbeeren oder Elefanten die Rede war, kann ich auch unter diesen Stichworten suchen. So verwende ich in Registern den Index im engeren Sinne des Wortes, indem ich ein Wort als Zeichen für das Vorhandensein anderer Wörter lese: Wo Rauch ist, ist Feuer.
Metatext nenne ich eigenständige Texte, die - wie Indexe in Büchern - Aussagen über andere Texte machen, die also quasi hinter den andern Texte stehen. Der einfachste Fall ist die Beschriftung eines Ordners oder der Name eines Directory im Computer. Wenn ich dafür beispielsweise den Text "Privat" schreibe, dann charakterisiere ich alle Dokumente, die in diesem Ordner oder Directory liegen, als privat. Ich mache die Meta-Aussage, dass diese Dokumente privat sind, obwohl in den Dokumenten das Wort privat nicht vorkommt. Mit Metatext kann man beliebige Sortierordnungen beschreiben, welchen man die Dokumente frei zuordnen kann. Die Metatexte folgen nicht aus den Texten, sondern werden den Texten - als Verzeichnisse - zugefügt. Die Inhalte der Metatexte beschreiben nicht die Texte, sondern im Falle von Ontologien die Welt und im Falle unserer MailTack-Constellation das Wissen des Konstrukteurs des Metatextes.
Man kann MailTack als Metatext-Maschine sehen, wenn man den Gesichtspunkt der Constellation betont. Diese Sicht dominierte die bisherige Entwicklung von MailTack, nicht zuletzt auch, weil MailTack im Rahmen des KnowNet-Projektes entwickelt wurde und dessen Perspektive einer Ontologie mindestens teilweise teilen musste, um als Projektteil Sinn zu machen. Geplant war schliesslich, die Constellations der MailTack-Benutzer in regelmässigen Abständen zusammenzuführen und als Basis für die Ontologie des Knowledgers zu verwenden.
Mit der Idee eines Wissens-Portfolio verbinden wir überdies eine Form von explizitem Wissen, wie sie sich in einer Liste von Kategorien niederschlagen kann. Die Constellation gibt leicht lesbar Auskunft über die Themen, die mich beschäftigen, weil sie als Metatext ein eigenständiges Dokument darstellt. Ein zentrales Motiv für MailTack war ja gerade das quasi automatisch anfallende kategoriale Wissen, das der Benutzer aus der Spiegelung seiner Tätigkeit gewinnen kann. Natürlich generiert jeder Benutzer von MailTack auch Wissen darüber, wie MailTack verbessert werden könnte, aber dieses konstruktive Wissen bleibt ohne bewusste Explikation implizit, weil der Benutzer das Programm "MailTack" nicht verändern kann.
In der nächsten Entwicklungsphase betrachten wir MailTack bewusster als Link-Maschine. Die Segmentierung der Texte und deren Verknüpfung zu Streams entsprechen der Hypertextphilosophie, nach welcher Texte in bedeutungsmässig eigenständige Einheiten zerlegt und mit Links verbunden werden (Todesco 1999). Die Streams und auch die Annotation, die man im MailTack zu den einzelnen Segmenten machen kann, basieren auf namenlosen Verknüpfungen von Textelementen, die praktisch einfach wieder grössere Textelemente erzeugen, nachdem die Segmente zuvor auseinander geschnitten wurden. Die diesen Verknüpfungen zugrundeliegende Logik bleibt völlig implizit oder realisiert formale Aspekte wie zeitliche Reihenfolgen, in welchen die Elemente geschrieben wurden.
Vannevar Bush, der den Link im Sinne einer maschinellen Textersetzung vorgeschlagen hat, erwog im Titel seiner Schrift "As we may think", dass er in Links denken würde. Wie sein Kopf funktioniert kann ich nicht beurteilen, seine Link-Maschine wurde weder von ihm noch von andern je gebaut. Sie ist allenfalls kategoriales Wissen geblieben. Die Link-Maschinen, die bislang wirklich gebaut wurden, verwenden die Linktechnik vorab in Registern und für die Navigation, also gerade nicht für Links. Die einzige Ausnahme davon bilden Lexika, die immerschon eine Hyperstruktur aufwiesen und Inbegriff jeder Wissenskultur sind. Da aber konventionelle Lexika konventionell als Nachschlagewerke verwendet werden, dienen sie viel mehr der Verwaltung von vorhandenem Wissen - auf welches auch dort über Register zugegriffen wird -, als der Bewusstwerdung, was man wie weiss. Manchmal schaue ich in alten Lexika, was man beispielsweise vor hundert Jahren schon wie gewusst hat, in neuen Lexika lese ich ganz selten mit diesem Bewusstsein.
Im Rahmen von KnowPort untersuchen wir, wie MailTack ein Link-Maschine werden kann. Im Unterschied zu Bush versuchen wir nicht eine erst beschriebene Maschine mit Verweisen auf unser Denken - von welchem wir wie Bush keine Ahnung haben - zu plausibilisieren, wir versuchen unsere Wissensprozesse zu erklären, indem wir Maschinen bauen, die als erklärende Mechanismen dienen können. Ich freue mich auf die Fortsetzung dieser Geschichte.
Bush, Vannevar, 1945. As We May Think. The Atlantic Monthly, 15, Nr. 176, 101-108
Nonaka, I. and H.Takeuchi (1995): The Knowledge-Creating Company. New York: Oxford University Press.
Rolf Todesco: Konstruktives Wissensmanagement im Hypertext. In: Knorr, Dagmar / Jakobs, Eva Maria (Hrsg.): Textproduktion. Hypertext, Text, Kontext, Frankfurt/M: Peter Lang, [Textproduktion und Medium; 4]. 1999